SonicVisionLM: Playing Sound with Vision Language Models
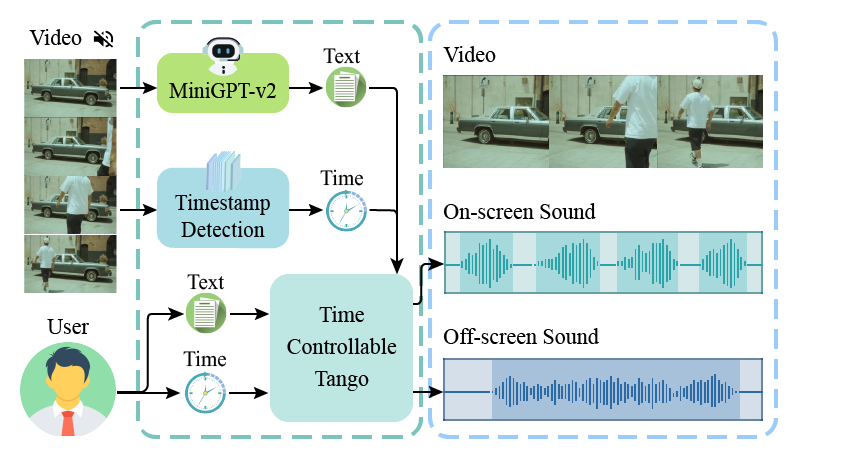
SonicVisionLM implements the automatic detection of in-picture voice generation and accepts the user's editing of this paper and time in the off-screen section. On-screen sound means sound originate from visual information. Off-screen sound not directly happened on the screen.
Abstract
There has been a growing interest in the task of generating sound for silent videos, primarily because of its practicality in streamlining video post-production. However, existing methods for video-sound generation attempt to directly create sound from visual representations, which can be challenging due to the difficulty of aligning visual representations with audio representations.
In this paper, we present SonicVisionLM, a novel framework aimed at generating a wide range of sound effects by leveraging vision language models. Instead of generating audio directly from video, we use the capabilities of powerful vision language models (VLMs). When provided with a silent video, our approach first identifies events within the video using a VLM to suggest possible sounds that match the video content. This shift in approach transforms the challenging task of aligning image and audio into more well-studied sub-problems of aligning image-to-text and text-to-audio through the popular diffusion models. To improve the quality of audio recommendations with LLMs, we have collected an extensive dataset that maps text descriptions to specific sound effects and developed temporally controlled audio adapters. Our approach surpasses current state-of-the-art methods for converting video to audio, resulting in enhanced synchronization with the visuals and improved alignment between audio and video components.
Framework Overview
SonicVisionLM presents a composite framework designed for the automatic recognition of on-screen sounds coupled with a user-interactive module for off-screen sounds editing. The blue dashed box and arrows in the figure represent the visual automation workflow: First, a silent video goes into MiniGPT-v2 where it figures out what's happening (text). Then, this video is processed by the visual network to capture the timestamp of on-screen sound events. After that, these two conditions are then entered into the Latent Diffusion Model with adapter to generate the sounds that match what's on screen. The purple dotted box and arrows show how users can add their own changes to create off-screen sounds.
Demos
conidtional generation
Target
Condition
stick scratch the dirt
CondFoleyGen
Ours
Target
Condition
stick hit the paper
CondFoleyGen
Ours
Target
Condition
stick hit the wood
CondFoleyGen
Ours
Target
Condition
stick scratch the leaves
CondFoleyGen
Ours
Target
Condition
stick scratch the metal
CondFoleyGen
Ours
Target
Condition
stick hit the plastic
CondFoleyGen
Ours
Target
Condition
stick scratch the dirt
CondFoleyGen
Ours
Target
Condition
stick hit the metal
CondFoleyGen
Ours
Target
Condition
stick scratch the cloth
CondFoleyGen
Ours
For CondFoleyGen, the condition is audio.
For SonicVisionLM(ours), the condition is text.
Evaluation criteria: check if model can change sound types based on conditions but still synchronize with the target action.
* These video clips are from Greatest Hits dataset
unconditional generation
GT
SpecVQGAN
DIFF-FOLEY
Ours
GT
SpecVQGAN
DIFF-FOLEY
Ours
GT
SpecVQGAN
DIFF-FOLEY
Ours
GT
SpecVQGAN
DIFF-FOLEY
Ours
GT
SpecVQGAN
DIFF-FOLEY
Ours
GT
SpecVQGAN
DIFF-FOLEY
Ours
GT
SpecVQGAN
DIFF-FOLEY
Ours
SpecVQGAN and SonicVisionLM(ours) can generate sounds for 10s. DIFF-FOLEY can generate sounds for 8s.The remaining 2s we fill in with blank audio, so hopefully that doesn't factor into the evaluation.
Evaluation criteria: the model's capability to accurately generate category-specific and time-synchronized longer sounds for slient videos
* These video clips are from CountixAV datase
Multi-soundtracks generation
original video (* This video clip is from Titanic)
Level 1 : blow a whistle
Level 2 : blow a whistle + waves
original video (* This video clip is from Léon)
Level 1 : door opening + footsteps
Level 2 : door opening squeakly + footstepsof leather shoes(time condition)
Level 3 : door opening squeakly + footstepsof leather shoes(time condition)+news report on TV + insert key to unlock the door
BibTeX
@article{xie2024sonicvisionlm,
title={SonicVisionLM: Playing Sound with Vision Language Models},
author={Xie, Zhifeng and Yu, Shengye and Li, Mengtian and He, Qile and Chen, Chaofeng and Jiang, Yu-Gang},
journal={arXiv preprint arXiv:2401.04394},
year={2024}
}